
Text generating AIs have not gotten the same level of publicity as image generating AIs, but they have arguably been around longer and are more pervasive in our everyday lives. Just think of all the chat bots that pop up and offer to answer your questions whenever you visit various websites. We have relied entirely on OpenAI’s GPT-3 language model to both come up with original story ideas and produce a large percentage of the text in our free stories. Using their Playground to write stories has very much been a learning process, so I thought it would be helpful for me to share what I have discovered so far.
Getting Started
The very first step is to get access to the language model. At time of writing, people can get free access to the Playground by requesting a beta-license from OpenAI. Once you have finished setting up your account, you will see Playground’s main interface.
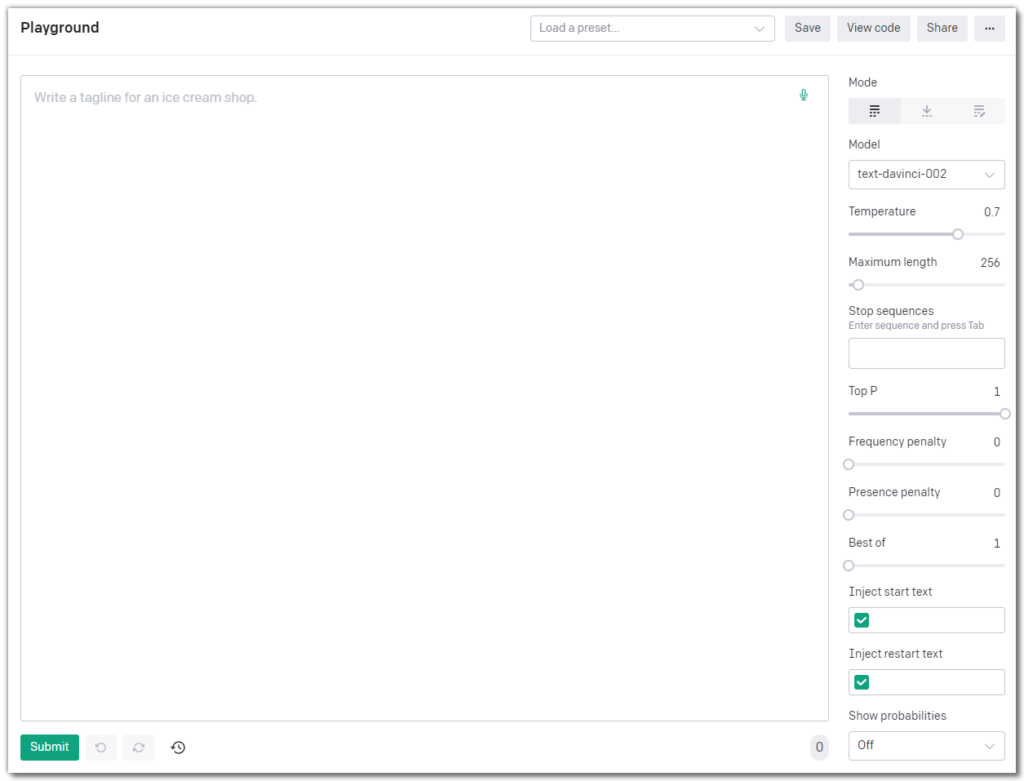
Pricing
While getting access to the OpenAI Playground is free, using the GPT-3 language models is not. They charge per 1,000 tokens used. A token is approximately 4 characters in English, which means that 1,000 tokens is roughly equivalent to about 750 words. The number of tokens in your prompt is displayed in the bottom right corner of the interface in a grey circle. You can set the number of tokens used across your prompt and output text with the Maximum Length setting that I describe in more detail below.
Pricing varies depending on which model you use, which I’ll cover in the next section.
OpenAI GPT-3 Parameters and Settings
Models
The writing content, style or type of assistance you want will determine what model you should select. Here is a quick summary of their advantages and disadvantages:
- Davinci
- Pros: Highest capability model; available in Insert and Edit modes; good for complex tasks and understanding text sentiment; training data is most recent (June 2021)
- Cons: Slowest of the four models; Costs the most per call at $0.02 / 1k tokens
- Curie
- Pros: Best at language translation, summarization and mimic training text sentiment and tone; only a tenth the cost of using Davinci at $0.002 / 1k tokens
- Cons: Not as good at analyzing complicated text at Davinci; training data from October 2019
- Babbage
- Pros: Good at sentence completion and brainstorming lists; faster than Davinci and Curie; costs only $0.0005 / 1k tokens
- Cons: Not good at complex tasks or text analysis; training data from October 2019
- Ada
- Pros: Great at generating large, random datasets of text; fastest of all the models; least expensive at $0.0004 / 1k tokens
- Cons: Only capable of very simple tasks; training data from October 2019
To help give an idea of the difference between the four models, here is an example I generated in the OpenAI Playground, using the same setting parameters and prompt from One Drop in the Ocean:
Prompt: Write the beginning of a short story about a drop in the ocean.
Davinci: Once upon a time, there was a drop in the ocean. It wasn’t much, just a little bit of water that had fallen from the sky, but it was enough to make a big splash in the ocean.
Curie: The sun was setting and the waves were crashing against the shore. The smell of salt water mixed with the scent of flowers in the air. It was a beautiful day, but there was something wrong.
Babbage: The ocean is a vast and infinite place. It’s the size of Earth and has the same temperature, but it’s also full of water droplets that can be as small as a millimeter and as large as a kilometer.
Ada: The ocean was a drop in the ocean. It was so small it seemed like it didn’t have a bottom. The water was very deep and the waves were very strong.
For the purposes of writing stories for Once Upon an Algorithm, I generally use either Da Vinci or Curie. Da Vinci seems like the most well-rounded AI and is capable of everything the other models are good at, but Curie seems better than Davinci at writing descriptive sentences that create a sense of atmosphere or drama. Both are decent at understanding example text and mimicking its style and tone. OpenAI provides more detail about the four models in their documentation.
Presets available in OpenAI Playground
There are several presets available in the drop down menu at the top of the interface:
- Grammatical Standard English
- Summarize for a 2nd Grader
- Text to Command
- Q&A
- English to Other Languages
- Parse Unstructured Data
- Classification
- Chat
Selecting a preset will autofill the text area with an example prompt and output to demonstrate how to use it. If you do not wish to use a preset, simply leave the drop down menu alone.
The one preset I occasionally use for writing kids stories is “Summarize for a 2nd grader.” Here is an example of how I used it for One Drop in the Ocean:

Mode
There are three types of mode available in the OpenAI Playground: Completion, Insert and Edit.
Completion is the bread and butter of this AI. You give it a prompt and the AI will attempt to complete it based on the example text (if any) you gave to train it. Here is Curie completing the beginning of the story it started above:
Prompt: The sun was setting and the waves were crashing against the shore. The smell of salt water mixed with the scent of flowers in the air. It was a beautiful day, but there was something wrong. A storm was brewing and it looked like it would be bad.
Curie: A woman was walking on the beach. She had long, blonde hair and blue eyes. She was wearing a white dress and sandals. She looked peaceful and happy, but there was something wrong with her too.
Insert is only available in the Davinci model. When you click on the insert icon, the interface bifurcates into an input (left) and output (right) side. You indicate where you want text inserted by adding [insert] into the text.
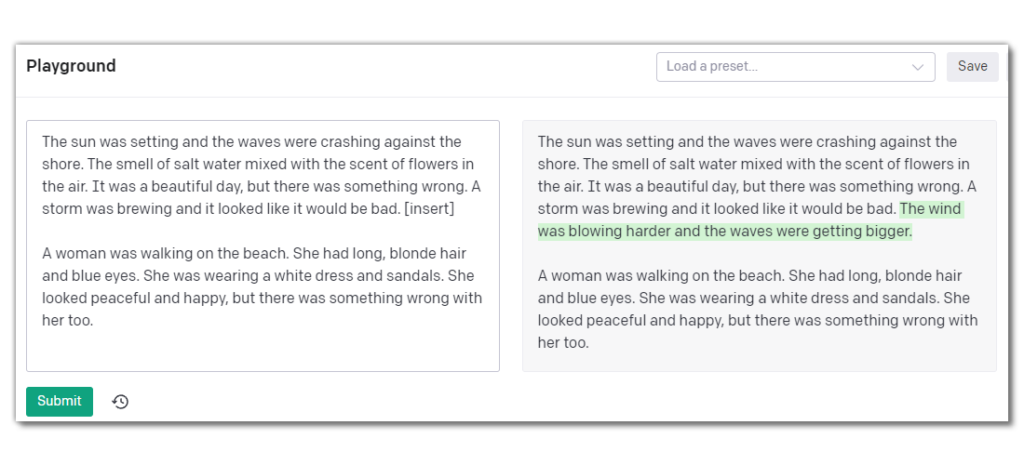
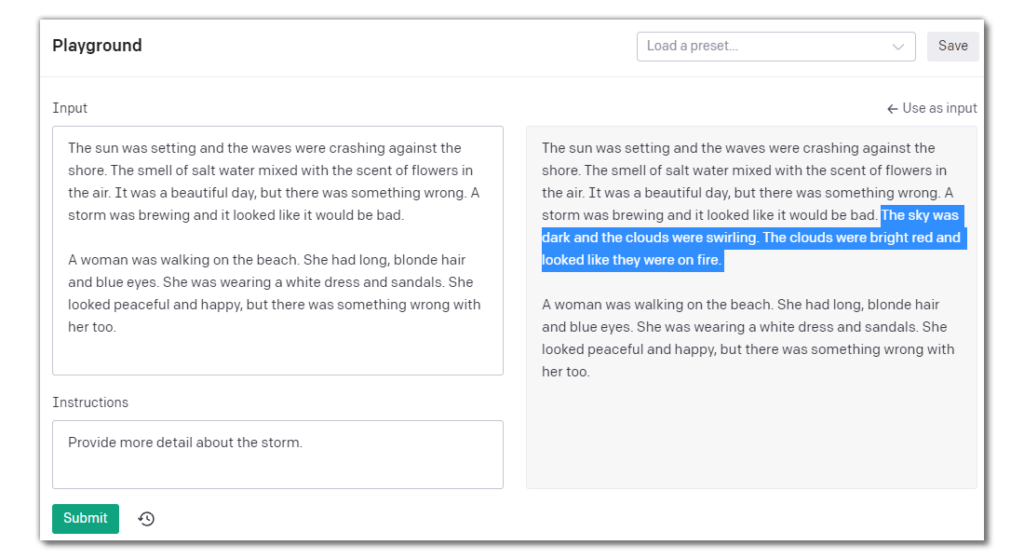
Edit has Davinci modify the provided text based on instructions you give it. I have the most variance in results using this mode. The only consistently good output I tend to get is when I ask Davinci to fix any grammatical errors in the text. Based on my limited experimentation, other instructions tend to work very similarly to the Completion and Insertion modes by adding text either at the end or in the middle.
GPT-3 Settings
Temperature
This setting is the one that controls the randomness or creativity of the output text. A temperature of 0 means that the output will always be exactly the same as the input text, whereas a temperature of 1 allows for the maximum amount of creativity. I tend to adjust temperature more than any other setting in the OpenAI Playground. Here are a couple examples of how it can affect the output:
Temperature = 0.2
Prompt: Suggest three plot ideas for a short story about a frog who goes on an adventure.
1. A frog who goes on an adventure to find a new home after his pond dries up.
2. A frog who goes on an adventure to find a mate after his last one dies.
3. A frog who goes on an adventure to escape from a predator.
Temperature = 1.0
Prompt: Suggest three plot ideas for a short story about a frog who goes on an adventure.
1. A frog who has been content with her life in her small pond suddenly finds herself thrust into the vast and dangerous open world beyond.
2. A frog who has always been a failure suddenly discovers she has latent magical powers that allow her to transform into a beautiful princess.
3. A frog who is usually very timid and shy takes a stand against a group of bullies who are making fun of her.
I combined some of these output suggestions to form the basis of my story Little Frog, Big Dragon.
Top P
Most of the information I have found about what Top P does tend to be extremely hand wavey. OpenAI’s description is: “Controls diversity via nucleus sampling.” The best non-technical explanation I could find is that Top P determines the number of random results the model considers for the output. Overall, the general consensus is that it contributes to the creativity level of the output text.
In my experience using the GPT-3 model in the OpenAI Playground, having both set to above 0.5 will give more interesting and varied results. Setting either Top P or Temperature to a low value will create very deterministic and often identical texts, regardless of what the other is set to.
For the examples below, I swear I did not simply copy/paste the exact same output across three setting combinations!
Top P=0, Temperature = 0.2:
1. A frog who goes on an adventure to find a new home after his pond dries up.
2. A frog who goes on an adventure to find a new food source after his usual diet of insects becomes scarce.
3. A frog who goes on an adventure to find a mate after his last one dies.
Top P = 0, Temperature = 1.0:
1. A frog who goes on an adventure to find a new home after his pond dries up.
2. A frog who goes on an adventure to find a new food source after his usual diet of insects becomes scarce.
3. A frog who goes on an adventure to find a mate after his last one dies.
Top P=1, Temperature = 0.2:
1. A frog who goes on an adventure to find a new home after his pond dries up.
2. A frog who goes on an adventure to find a new food source after his usual diet of insects becomes scarce.
3. A frog who goes on an adventure to find a mate after his last one dies.
Top P=1, Temperature = 1.0:
1. A frog who goes on an adventure to find a new pond to call home.
2. A frog who goes on an adventure to discover the source of a mysterious noise.
3. A frog who goes on an adventure to find the perfect spot to take a nap.
Maximum Length
This setting determines the maximum number of tokens the generated text will have. In English, one token is equivalent to about 4 characters. Setting a higher response length does not necessarily mean the output will be that long. In my experience, the vast majority of the time, it will be shorter.
However, if you have set a particularly short response length, such as less than 100, the AI will not always adjust its output to accommodate that either. Instead, the output text will simply get cut off mid sentence when it reaches the specified response length, as shown in the following example from Clara in the City.
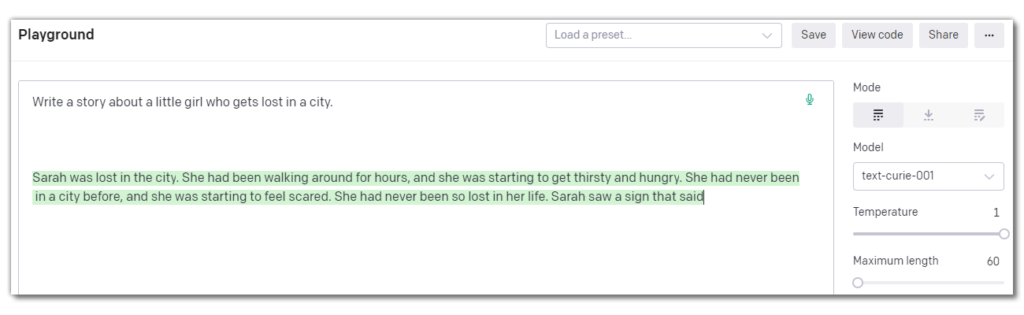
It is worth noting that each of the models are limited to a certain number of tokens. Davinci can do up to 4000 tokens while Curie, Babbage and Ada are limited to 2,048 tokens.
Stop Sequence
You can enter a specific string of characters to tell GPT-3 to stop generating completions. In my story writing and brainstorming, I have never needed to use this particular setting. My understanding is it is primarily useful in two situations:
- You want to generate an output based on example text you’ve provided that repeatedly uses the same words
- You use stop length in combination with the Inject Start Text parameter to get a specific length or type of output
In both scenarios I just described, you can predict with high certainty that the AI will use the characters specified in the stop sequence in its generated completion.
Inject Start Text
This parameter is useful if you want the completion text to always start with a known prefix, which is nice when creating conversations between two characters. To give a specific example, in Little Frog, Big Dragon, there is a verbal exchange between a frog and a dragon. To train the language model in OpenAI to understand the topic of the conversation, I provide some training text and then a command prompt. In the image below, the inject start text is set to “Frog:” because I want the frog to be the initiator of the confrontation.

Inject Restart Text
This variable is great for generating multiple short interactions without having to type the same prompt over and over. Let’s say I want to use GPT-3 to come up with a bunch of short, lame jokes that all follow a Q&A format. All I have to do is add, “Question:” as the Inject restart text and then hit the Submit button over and over for the AI to pump out a bunch of jokes.

Frequency and Presence Penalty
These settings control the likelihood of repeating the same words or phrases by penalizing tokens based on how many times they have already appeared in the text. The higher the penalty, the more creative and diverse the output will be in both vocabulary and topic.
Here is an excerpt of text written by GPT-3 when both the Frequency and Presence penalties are set to 0:
The girl had been walking for hours, and she was getting tired. She had been following the river, but it had meandered so much that she was now completely lost. She sat down on a rock to rest. She didn’t know which way to go. She was getting scared. She heard a noise, and she got up to see what it was. It was a bear.
The sentence structure in this text is quite similar and short, and uses many words over and over again. Using an online readability calculator, the above text has a Flesch-Kincaid grade level of only 1.5, which means that its sentence structure and vocabulary is representative of a 1st or 2nd grader in the United States.
Compare that to when the Frequency and Presence penalties are increased to 2:
The girl had been walking along the river for hours, trying to find her way home. She was getting tired and hungry, and she knew she couldn’t keep going much longer. Finally, she came to a fork in the river. She didn’t know which way to go. She sat down on the bank of the river and began to cry. Suddenly, she heard a noise behind her. She turned around and saw a big bear standing there looking at her.
The text produced using higher penalty settings is significantly more interesting and varied, with a Flesch-Kincaid grade level of 3.2. This means that adjusting the penalty values is a good way to control the maturity level of the output to accommodate the age of your target audience.
Best of
This setting specifies how many completions to run server side. You can have it do up to 20 completions, but it will only output the one that GPT-3 considers the best. Note that OpenAI still charges you for the tokens it generates even though you don’t get to see them, so this setting can significantly multiply the cost of using Playground. Because of the opacity and increased cost, I have never set this higher than 1. If you do increase this variable above 1, Playground will stop streaming the output text in real time and instead display it all at once.
Show Probabilities
This drop down menu appears at the very bottom. If you select one of the options before submitting your prompt, the resulting output will have each token colored based on the likelihood of its use. Red tokens indicate words that were more likely to be used than green words. Left-clicking on a token will bring up a pop-up box that displays all the options that were considered and the probability they would have been selected.
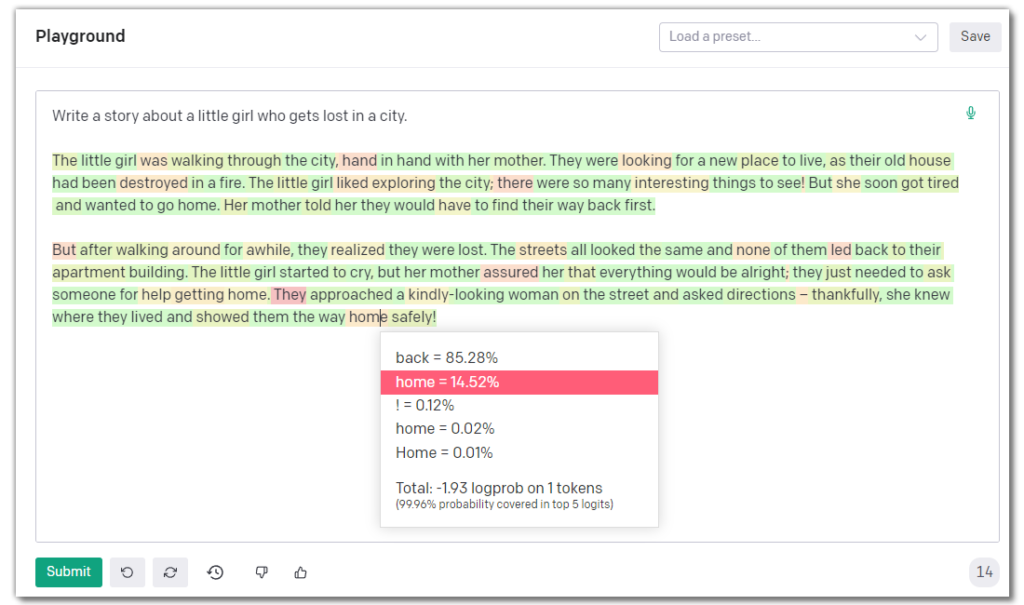
For my story writing, I find this mode useful if I like the overall output but want to substitute some words with synonyms.
Related Articles
Why AI makes sense for writing illustrated stories for kids
Learn how we used GPT-3 to write the text for Little Frog, Big Dragon, plus funny bloopers
How we used GPT-3 for idea generation and plot development in Sarah in the Secret Garden